WebGL2入门
😀 注意WebGL2几乎100%向后兼容WebGL1。 就是说,一旦启用WebGL2,原来WebGL1写的代码还是会如预期的那样执行。
📝 WebGL
WebGL通常被认为是一种3D API。 人们认为“我会使用了WebGL魔法,我就会拥有酷酷的3D技能”。 实际上WebGL仅仅是栅格化(rasterization)引擎。它会基于你的代码来画点,线条和三角形。 而你需要使用点、线、三角形组合来完成复杂的3D任务。
WebGL是在GPU上运行的。在GPU上运行的WebGL代码是以一对函数的形式,分别叫做点着色器(Vetex Shader)和片段着色器(Fragment Shader). 他们是用一种类似C++的强类型语言GLSL编写的。这一对函数组合被叫做程序(Program)。
点着色器的任务是计算点的的位置。基于函数输出的位置,WebGL能够栅格化(rasterize)不同种类的基本元素,如点、线和三角形。当栅格化这些基本元素的同时,也会调用第二种函数:片段着色器。它的任务就是计算当前正在绘制图形的每个像素的颜色。
几乎所有的WebGL API是为这些函数对的运行来设置状态。你需要做的是:设置一堆状态,然后调用gl.drawArrays和gl.drawElements在GPU上运行你的着色器。
这些函数需要用到的任意数据都必须提供给GPU。 着色器有如下四种方法能够接收数据。
- 属性(Attributes),缓冲区(Buffers)和顶点数组(Vetex Arrays)
- Uniforms
- 纹理(Textures)
- Varyings
webgl 程序工作流程
1. 顶点着色器代码
#version 300 es
in vec4 a_position;
void main(){gl_Position = a_position}
2. 片段着色器代码
#version 300 es
precision highp float;
out vec4 outColor;
void main(){outColor = vec4(1.)}获取WebGL2渲染上下文
-
HTMLCanvasElement
<canvas id="c"></canvas> -
查找并创建WebGL2RenderingContext
const gl = $$('#c').getContext('webgl2',{ alpha:true, // boolean值表明canvas包含一个alpha缓冲区。 antialias:true, // boolean值表明是否开启抗锯齿 depth: true, // 值表明绘制缓冲区包含一个深度至少为 16 位的缓冲区。 failIfMajorPerformanceCaveat: false, // 表明在一个系统性能低的环境是否创建该上下文的boolean值。 // high-performance高性能模式。 "low-power": 节能模式。"default":自动选择 powerPreference:'high-performance', // 默认使用default premultipliedAlpha: true, // 表明排版引擎将假设绘制缓冲区包含预混合 alpha 通道的boolean值。 preserveDrawingBuffer: true, // 如果这个值为true缓冲区将不会被清除,会保存下来,直到被清除或被使用者覆盖。 stencil:true // 表明绘制缓冲区包含一个深度至少为 8 位的模版缓冲区boolean值。 })
获取shaderProgram
-
编译着色器代码
const shader = gl.createShader(gl.VERTEX_SHADER) gl.shaderSource(shader,source) gl.compileShader(shader) if(!gl.getShaderParameter(shader,gl.COMPILE_STATUS)){ console.log(gl.getShaderInfoLog(shader)) gl.deleteShader(shader) } -
链接两个着色器合成一个程序
const program = gl.createProgram() gl.attachShader(program,vertexShader) gl.attachShader(program,fragmentShader) gl.linkProgram(program) if(!gl.getProgramParameter(program,gl.LINK_STATUS)){ console.log(gl.getProgramInfoLog(program)) gl.deleteProgram(program) }
传递顶点数据
-
获取属性下标位置
const positionAttributeLocation = gl.getAttribLocation(program,'a_position') -
创建VAO
// 数据存放到缓存区后,接下来需要告诉属性如何从缓冲区取出数据。 // 首先,我需要创建属性状态集合:顶点数组对象(Vertex Array Object)。 const vao = gl.createVertexArray() // 为了使所有属性的设置能够应用到WebGL属性状态集, // 我们需要绑定这个顶点数组到WebGL。 gl.bindVertexArray(vao); -
提交数据
// 要从缓存区中传递数据给属性,需要先创建缓冲区 const positionBuffer = gl.createBuffer(); // WebGL通过绑定点来处理许多WebGL资源。 // 你可以认为绑定点是WebGL内部的全局变量 // 绑定一个资源到某个绑定点 gl.bindBuffer(gl.ARRAY_BUFFER,positionBuffer) // WebGL需要强类型数据, // 需要用new Float32Array(positions)创建32位的浮点数数组 // 然后用gl.bufferData函数将数组数据拷贝到GPU上的positionBuffer里面。 // 因为前面把positionBuffer绑定到了ARRAY_BUFFER,所以我们直接使用绑定点。 // gl.STATIC_DRAW 告诉WebGL我们不太可能去改变数据的值。 // gl.DYNAMIC_DRAW 告诉WebGL经常更改和使用 gl.bufferData(gl.ARRAY_BUFFER,new Float32Array([0,0, 0,0.5, 0.7,0]),gl.STATIC_DRAW) // 还需要启用属性。如果没有开启这个属性,这个属性值会是一个常量。 gl.enableVertexAttribArray(positionAttributeLocation) // 需要设置属性值如何从缓存区取出数据。 const size = 2; // 2 components per iteration const type = gl.FLOAT; // the data is 32bit floats const normalize = false; // don't normalize the data const stride = 0; // 0 = move forward size * sizeof(type) each iteration to get the next position const offset = 0; // start at the beginning of the buffer gl.vertexAttribPointer( positionAttributeLocation, size, type, normalize, stride, offset) // gl.vertexAttribPointer 的隐含部分是它绑定当前的ARRAY_BUFFER到这个属性。 -
提交顶点索引
const indicesBuffer = gl.createBuffer() gl.bindBuffer(gl.ELEMENT_ARRAY_BUFFER,indicesBuffer) gl.bufferData(gl.ELEMENT_ARRAY_BUFFER,indices,gl.STATIC_DRAW)
创建MVP矩阵
-
projectMatrix
let aspect = gl.canvas.clientWidth / gl.canvas.clientHeight const zNear = 1 const zFar = 2000 const projectMatrix = mat4.create() // 这是透视矩阵,正交矩阵也有类似的创建方法 mat4.perspective(projectMatrix,degToRad(60),aspect,zNear,zFar) -
viewMatrix
// viewMatrix在有些框架下是通过inverse相机矩阵来的 const cameraPosition = vec3.fromValues(0,0,4) const lookAtOrigin = vec3.fromValues(0,0,0) const headIsUp = vec3.fromValues(0,1,0) const cameraMatrix = mat4.lookAt( mat4.create(), cameraPosition, lookAtOrigin, headIsUp ) -
modelMatrix
// 模型矩阵一般用来处理模型的旋转平移缩放, // 实际上在顶点着色器中就可以直接实现旋转平移缩放, // 使用矩阵是为了不考虑旋转平移缩放的顺序同时方便处理多级联动 const currentScale = 5. const modelMatrix = mat4.create() mat4.scale(modelMatrix,modelMatrix,[currentScale+5,currentScale,currentScale]) mat4.translate(modelMatrix,modelMatrix,[0,0,-1]) mat4.rotateX(modelMatrix,modelMatrix,degToRad(1)) mat4.rotateZ(modelMatrix,modelMatrix,degToRad(0.5))
传递Uniform
-
简单数据
const location = gl.getUniformLocation(program,'location') // 简单数据是指int float vec mat 这些数据 gl.uniform[1234][uif][v](location,value) // <https://developer.mozilla.org/zh-CN/docs/Web/API/WebGL2RenderingContext/uniform> // ui 意为无符号整数, i 意为整数,f 意为浮点数, 并且 v 意为矢量。 // 并不是所有的组合都是有效的:u 不能是 f的组合。详见下方语法表格。 // 用正则表达式概括语法:uniform[1234](u?i|f)v? gl.uniformMatrix[234]x[234]fv(location,false,value) // <https://developer.mozilla.org/zh-CN/docs/Web/API/WebGL2RenderingContext/uniformMatrix> // 这个方法不用 2x2, 3x3, 和 4x4 版本 . 他们通常用2, 3, 和4, 分别表示,详见下方语法。 -
纹理数据
// 纹理数据一般指sampler2D和sampler3D数据 const location = gl.getUniformLocation(program,'sampler') const texture = gl.createTexture() // gl.activeTexture(GL_TEXTURE_LOCATION) gl.bindTexture(gl.TEXTURE_2D,texture) gl.texImage2D( gl.TEXTURE_2D, 0, // mip level gl.LUMINANCE, // internal format 4, // width 4, // height 0, // border gl.LUMINANCE, // format gl.UNSIGNED_BYTE, // type new Uint8Array([ // data 192, 128, 192, 128, 128, 192, 128, 192, 192, 128, 192, 128, 128, 192, 128, 192, ]) ); const linearSampler = gl.createSampler() gl.samplerParameteri(linearSampler, gl.TEXTURE_MIN_FILTER, gl.LINEAR) const nearestSampler = gl.createSampler(); gl.samplerParameteri(nearestSampler, gl.TEXTURE_MIN_FILTER, gl.NEAREST); gl.samplerParameteri(nearestSampler, gl.TEXTURE_MAG_FILTER, gl.NEAREST); gl.generateMipmap(gl.TEXTURE_2D); gl.bindTexture(gl.TEXTURE_2D, null); const u_texture = gl.getUniformLocation(program,'u_sampler') const texUint = 0 // 使用第几个插槽 一般来说不少于八个 // 获取最大贴图可用量 // gl.getParameter(gl.MAX_COMBINED_TEXTURE_IMAGE_UNITS); gl.activeTexture(gl.TEXTURE0+texUint) gl.bindTexture(gl.TEXTURE_2D,texture) gl.bindSampler(texUint,nearestSampler) gl.uniform1i(u_texture,texUint) //这里是偏移值 0-35 不是gl.TEXTURE0+texUint的地址
gl渲染配置
-
光栅化过程中的配置项
// 通过设置gl_Position, 我们需要告诉WebGL如何从剪辑空间转换值转换到屏幕空间。 // 为此,我们调用gl.viewport并将其传递给画布的当前大小。 gl.viewport(0, 0, gl.canvas.width, gl.canvas.height); gl.clearColor(baseColor[0],baseColor[1],baseColor[2],1) gl.enable(gl.CULL_FACE); gl.enable(gl.DEPTH_TEST);
渲染
-
渲染
gl.useProgram(program) gl.bindVertexArray(vao) // 对于没有顶点索引的 gl.drawArrays(gl.TRIANGLES,0,position.length/3) // 有顶点索引的 gl.drawElements(gl.TRIANGLES,indices.length,gl.UNSIGNED_SHORT,0)
## CPU
- shader创建
- 加载shader
- gl.createShader
- gl.shaderSource
- gl.compileShader
- 创建shaderProgram
- gl.createProgram
- gl.attachShader
- gl.bindAttribLocation
- gl.linkProgram
- 传递数据
- vertex
- gl.getAttribLocation ~~获取AttribLocation,创建vao并进行一系列vertex操作,操作结束后调用 bindVertexArray(null)解绑~~
- gl.createVertexArray *Create a vertex array object (attribute state)*
- gl.bindVertexArray *and make it the one we're currently working with*
- gl.createBuffer *Create a buffer*
- gl.bindBuffer *Bind it to ARRAY_BUFFER (think of it as ARRAY_BUFFER = positionBuffer)*
- gl.bufferData *Fill the current ARRAY_BUFFER buffer*
- gl.enableVertexAttribArray *Turn on the attribute*
- gl.vertexAttribPointer() *ell the attribute how to get data out of positionBuffer (ARRAY_BUFFER)*
- gl.bindVertexArray(null) *解绑*
- uniform
- gl.getUniformLocation *look up uniform locations*
- gl.uniformMatrix4fv *Set the matrix.*
- texture
- gl.createTexture *Create a texture.*
- gl.activeTexture *use texture unit 0*
- gl.bindTexture *bind to the TEXTURE_2D bind point of texture unit 0*
- gl.texImage2D *Fill the texture*
- gl.texParameteri
- gl.generateMipmap
## GPU
- gl配置
- gl.viewport
- gl.enable gl.DEPTH_TEST/gl.CULL_FACE
- 每帧操作
- gl.useProgram
- gl.bindVertexArray
- MVP计算
- cameraMatrix
- lookAt(position,target,up)
- viewMatrix
- cameraMatrix.inverse()
- projectionMatrix
- perspective(FOV,aspect,zNear,zFar)
- modelMatrix
- rotate
- scale
- offset
- darwArrays(primitiveType,offset,count)
- primitiveType = gl.TRIANGLES
- offset = 0
- count = A GLsizei specifying the number of indices to be rendered.(要渲染的索引数量)矩阵
OpenGL本身要求4x4矩阵的16个值在内存中是连续的,因此在C++我们可以创建一个结构或类。
矩阵变换的意义在于对层级变换的操作上(地月太阳,树枝运动)
矩阵运算从右向左解释
// 将矩阵转换到裁剪空间内
matrix = m3.projection(gl.canvas.clientWidth,gl.canvas.clientHeight)
// 平移到tx,ty
matrix = m3.translate(matrix, tx, ty);
// 空间绕tx,ty旋转
matrix = m3.rotate(matrix, rotationInRadians);
// 在此之前的操作上,x方向缩放sx,y方向缩放sy
matrix = m3.scale(matrix, sx, sy);在着色器中执行gl_Position = matrix * position;,position被直接转换到这个空间。
gl_Position = matrix * position;体渲染
摘抄“GPU Programming And Cg Language Primer 1rd Edition” 中文名“GPU编程与CG语言之阳春白雪下里巴人”
M.Levoy 在文章 “Display of surfaces from volume data”( 文献【 14 】 ) 中提到 “volume rendering describes a wide range of techniques for generating images from three-dimensional scalar data” ,翻译过来就是 “ 体绘制描述了一系列的 “ 根据三维标量数据产生二维图片 ” 的技术 ” 。
体绘制与科学可视化
科学可视化技术是运用计算机图形学、图像处理、计算机视觉等方法,将科学、工程学、医学等计算、测量过程中的符号、数字信息转换为直观的图形图像,并在屏幕上显示的理论、技术和方法。体绘制是科学可视化领域中的一个技术方向。
体绘制应用领域
人类发展史上的重大技术带来的影响大致分为两种:其一,技术首先改变生活本身,然后改变人类对世界的看法,例如电视、电话等;还有一种技术,是首先改变人类对世界的看法,然后改变生活本身,例如伦琴射线、望远镜。
体绘制技术应该属于后者,通过改变所见,而改变生活。体绘制计算的重要意义,首先在于可以在医疗领域,有助于疾病的诊断,这一点应该不用多说,计算机断层扫描( CT )已经广泛应用于疾病的诊断。医疗领域的巨大需求推动了体绘制技术的告诉发展,如果了解 CT 的工作原理,也就大致了解了体绘制技术原理和流程,其二,体绘制计算可以用于地质勘探、气象分析、分子模型构造等科学领域。我在工作期间承担的一个较大的项目便是有关 “ 三维气象可视化 ” ,气象数据通常非常庞大,完全可以号称海量数据,每一个气压面上都有温度、湿度、风力风向等格点数据,气象研究人员希望可以同时观察到很多气压面的情况,这时就可以采用体绘制技术,对每个切面(气压面)进行同时显示。
体绘制技术也能用于强化视觉效果,自然界中很多视觉效果是不规则的体,如流体、云、烟等,它们很难用常规的几何元素进行建模,使用粒子系统的模拟方法也不能尽善尽美,而使用体绘制可以达到较好的模拟效果。
往往有初学者会分不清 “ 体绘制技术 ” 以及 “ 透明光照模型 ” 之间的区别。这个问题很有意思。实际上,体绘制技术与透明光照模型在感性认识上十分类似,在很多教程中对体绘制技术的阐述也涉及到透明物体。但是,透明光照模型,一般侧重于分析光在透明介质中的传播方式(折射,发散,散射,衰减等),并对这种传播方式所带来的效果进行模拟;而体绘制技术偏重于物体内部层次细节的真实展现。举例而言,对于一个透明的三棱镜,使用透明光照模型的目的在于 “ 模拟光的散射,折射现象(彩虹) ” ;而对于地形切片数据或者人体数据,则需要使用体绘制技术观察到其中的组织结构。此外,在实现方式上,透明光照模型一般是跟踪光线的交互过程,并在一系列的交互过程中计算颜色值;而体绘制技术是在同一射线方向上对体数据进行采样,获取多个体素的颜色值,然后根据其透明度进行颜色的合成。
总的来说,透明光照模型侧重于光照效果展现,并偏向艺术化;而体绘制技术侧重展现物质内部细节,要求真实!
体绘制与光照模型
尽管光照模型通常用于面绘制,但是并不意味着体绘制技术中不能使用光照模型。实际上 , 体绘制技术以物体对光的吸收原理为理论基础,在实现方式上,最终要基于透明度合成计算模型。此外,经典的光照模型,例如 phong 模型, cook-torrance 模型都可以做为体绘制技术的补充,完善体绘制效果,增强真实感。
体数据( Volume Data )
学习任何一门技术,首先要弄清楚这项技术的起源以及数据来源。技术的起源也就是技术最原始的需求,最原始的发展动力,了解了这一点就了解了这项技术的价值。而了解一门技术的数据来源,就把握了技术的最初脉络,是 “ 持其牛耳 ” 的一种方法,正如软件工程中的数据流分析方法一般。
我很想说,体数据与面数据的区别,就好像一个实心的铁球和一个空心的兵乓球的区别。不过这个比喻很显然有点俗,很难让人相信作者(我)是一个专业人士。于是我决定还是将与体数据相关的专业术语都阐述一遍。
不过,在此之前,我需要先消除大家的恐惧感,研究表明,动物对于未知事物总是存在恐惧感,这也是阻碍进一步学习的关键所在。体数据不是什么特别高深的火星符号,它是对一种数据类型的描述,只要是包含了体细节的数据,都可以称之为体数据。举个例子,有一堆混凝土,其中包含了碳物质( C )若干,水分子( H20 )若干,还有不明化学成分的胶状物,你用这种混凝土建造了块方砖,如果存在一个三维数组,将方砖 X 、 Y 、 Z 方向上的物质分布表示出来,则该数组可以被称为体数据。不要小看上面这个比喻,体数据本质上就是按照这个原理进行组织的!
体数据一般有 2 种来源:
- 科学计算的结果,如:有限元的计算和流体物理计算;
- 仪器测量数据,如: CT 或 MRI 扫描数据、地震勘测数据、气象检测数据等。
与体数据相关的专业术语有:体素( Voxel )、体纹理( Volume Texture )。尤其要注意:所谓面数据,并不是说二维平面数据,而是说这个数据中只有表面细节,没有包含体细节,实际上体数据和面数据的本质区别,在于是否包含了体细节,而不是在维度方面。
体素( Voxel )
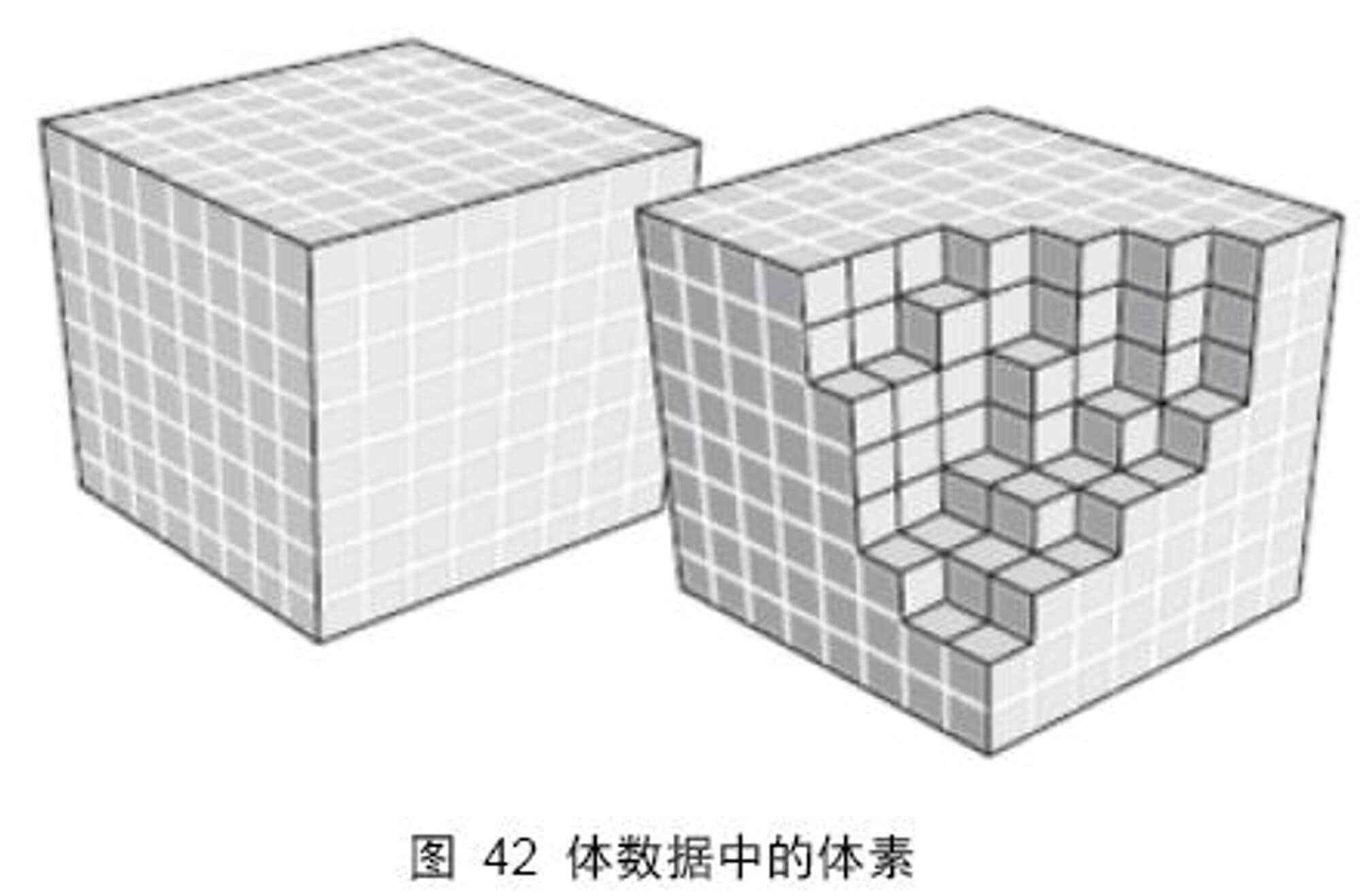
即 “ 体素,是组成体数据的最小单元,一个体素表示体数据中三维空间某部分的值。体素相当于二维空间中像素的概念 ” 。 图 42 中每个小方块代表一个体素。体素不存在绝对空间位置的概念,只有在体空间中的相对位置,这一点和像素是一样的。
通常我们看到的体数据都会有一个体素分布的描述,即,该数据由 个体素组成,表示该体数据在 X 、 Y 、 Z 方向上分别有 n 、 m 、 t 个体素。在数据表达上,体素代表三维数组中的一个单元。假设一个体数据在三维空间上 个体素组成,则,如果用三维数组表示,就必须在每一维上分配 256 个空间。
在实际的仪器采样中,会给出体素相邻间隔的数据描述,单位是毫米( mm ),例如 0.412mm 表示该体数据中相邻体素的间隔为 0.412 毫米 。
体纹理( Volume Texture )
体数据最主要的文件格式是 “ 体纹理( volume texture ) ” !故而,非常有必要对体纹理的概念进行详细的阐述。
目前,学术性文章中关于体纹理的概念描述存在不小的混乱,很多书籍或者网页资料没有明确的区分 2d texture , 3d texture , volume texture 之间的区别。导致不少人认为 “ 只要是用于三维虚拟或仿真技术中的纹理都称之为 3d texture” 。这是一个误会。纹理上的 2 , 3 维之分本质上是根据其所描述的数据维数而定的,所谓 2d texture 指的是纹理只描述了空间的面数据,而 3d texture 则是描述了空间中的三维数据。 3d texture 另一个较为学术化的名称是: volume texture 。
三维纹理,即体纹理,是传统 2D 纹理在逻辑上的扩展。二维纹理是一张简单的位图图片,用于为三维模型提供表面点的颜色值;而一个三维纹理,可以被认为由很多张 2D 纹理组成的,用于描述三维空间数据的图片。三维纹理通过三维纹理坐标进行访问
从上面这句话,可以得到两点信息:
- 三维纹理和体纹理是同一概念;三维纹理和二维纹理是不同的;
- 三维纹理通过三维纹理坐标进行访问。
这时可能会有人提出问题了,图片都是平面的,怎么能表示三维数据?请注意,我们通常所看到的图片确实都是平面的,但是并不意味着 x,y 平面上的像素点不能存放三维数据,举一个例子:在高级语言编程中,我们完全可以用一维数组去存放三维数组中的数据,只要按照一定规则存放即可!
按照一定规则将三维数据存放在 XY 像素平面所得到的纹理,称之为 volume texture 。
体数据通常是由 CT 仪器进行扫描得到的,然后保存在图片的像素点上。目前国际上比较常用的体纹理格式有,基于 DirectX 的 .dds 格式和 .raw 格式。注意,很多人会将 .raw 格式当作摄像器材使用的那种格式,其实这两个格式的后缀虽然都是 .raw ,但是其数据组织形式是不同的。用于体纹理的 .raw 格式,存放的是三维数据,用于摄像器材的 .raw 格式只是普通的二维图片。
由于在国内的网站上很难找到体数据,所以下面我给出几个国外的网址,这些网址提供用于教学和研究只用的体纹理数据(只能用于教学和研究)。
- http://wwwvis.informatik.uni-stuttgart.de/~engel/pre-integrated/data.html
- http://www9.informatik.uni-erlangen.de/External/vollib/
- http://www.volren.org/
体绘制算法
国际上留下的体绘制算法主要有:光线投射算法( Ray-casting )、错切 - 变形算法( Shear-warp )、频域体绘制算法( Frequency Domain )和抛雪球算法( Splatting )。其中又以光线投射算法最为重要和通用。
究其原因,无外乎有三点:其一,该算法在解决方案上基于射线扫描过程,符合人类生活常识,容易理解;其二,该算法可以达到较好的绘制效果;其三,该算法可以较为轻松的移植到 GPU 上进行实现,可以达到实时绘制的要求。
光线投射算法原理
光线投射方法是基于图像序列的直接体绘制算法。从图像的每一个像素,沿固定方向(通常是视线方向)发射一条光线,光线穿越整个图像序列,并在这个过程中,对图像序列进行采样获取颜色信息,同时依据光线吸收模型将颜色值进行累加,直至光线穿越整个图像序列,最后得到的颜色值就是渲染图像的颜色。
为什么在上面的定义是穿越 “ 图像序列 ” ,而不是直接使用 “ 体纹理 ” ?原因在于,体数据有多种组织形式,在基于 CPU 的高级语言编程中,有时并不使用体纹理,而是使用图像序列。在基于 GPU 的着色程序中,则必须使用体纹理。这里所说的图像序列,也可以理解为切片数据。
尤其要注意:光线投射算法是从视点到 “ 图像序列最表面的外层像素 ” 引射线穿越体数据,而不少教程中都是糊里糊涂的写到 “ 从屏幕像素出发 ” ,这种说法太过简单,而且很容易让人误解技术的实现途径,可以说这是一种以讹传讹的说法!从屏幕像素出发引出射线,是光线跟踪算法,不是光线投射算法。
体绘制中的光线投射方法与真实感渲染技术中的光线跟踪算法有些类似,即沿着光线的路径进行色彩的累计。但两者的具体操作不同。首先,光线投射方法中的光线是直线穿越数据场,而光线跟踪算法中需要计算光线的反射和折射现象。其次,光线投射算法是沿着光线路径进行采样,根据样点的色彩和透明度,用体绘制的色彩合成算子进行色彩的累计,而光线跟踪算法并不刻意进行色彩的累计,而只考虑光线和几何体相交处的情况;最后,光线跟踪算法中光线的方向是从视点到屏幕像素引射线,并要进行射线和场景实体的求交判断和计算,而光线投射算法,是从视点到物体上一点引射线( 16.1.2 节会进行详细阐述),不必进行射线和物体的求交判断。
对于光线投射算法的描述可能太过简单,会引起一些疑惑,不过这是正常的,有了疑惑才会去思考解决之道,最怕看了以后没有任何疑惑,那只是浮光掠影似的一知半解,而不是真正的了然于胸。
吸收模型
几乎每一个直接体绘制算法都将体数据当作 “ 在某一密度条件下,光线穿越体时,每个体素对光线的吸收发射分布情况 ” 。这一思想来源于物理光学,并最终通过光学模型( Optical Models )进行分类描述。为了区别之前的光照渲染模型,下面统一将 Optical Model 翻译为光学模型。
文献【 15 】中对大多数在直接体绘制算法中使用的重要光学模型进行了描述,这里给出简要概述。
- 吸收模型( Absorption only ):将体数据当作由冷、黑的体素组成,这些体素对光线只是吸收,本身既不发射光线,也不反射、透射光线;
- 发射模型( Emission only ):体数据中的体素只是发射光线,不吸收光线;
- 吸收和发射模型( Absorption plus emission ):这种光学模型使用最为广泛,体数据中的体素本身发射光线,并且可以吸收光线,但不对光线进行反射和透射。
- 散射和阴影模型( Scattering and Shading/shadowing ):体素可以散射(反射和折射)外部光源的光线,并且由于体素之间的遮挡关系,可以产生阴影;
- 多散射模型( Multiple Scattering ):光线在被眼睛观察之前,可以被多个体素散射。
通常我们使用 吸收和发射模型( Absorption plus emission )。为了增强真实感,也可以加上阴影(包括自阴影)计算。
光线投射算法若干细节之处
光线如何穿越体纹理
这一节中将阐述光线如何穿越体纹理。这是一个非常重要的细节知识点,很多人就是因为无法理解 “ 体纹理和光线投射的交互方式 ” 而放弃学习体绘制技术。
前面的章节似乎一直在暗示这一点:通过一个体纹理,就可以进行体渲染。我最初学习体绘制时,也被这种暗示迷惑了很久,后来查找到一个国外的软件,可以将体纹理渲染到立方体或者圆柱体中,这时我才恍然大悟:体纹理并不是空间的模型数据,空间体模型(通常是规则的立方体或圆柱体)和体纹理相互结合才能进行体渲染。
举例而言,我们要在电脑中看到一个纹理贴图效果,那么至少需要一张二维的纹理和一个面片,才能进行纹理贴图操作。这个面片实际上就是纹理的载体。
同理,在体绘制中同样需要一个三维模型作为体纹理的载体,体纹理通过纹理坐标(三维)和模型进行对应,然后由视点向模型上的点引射线,该射线穿越模型空间等价于射线穿越了体纹理。
通常使用普通的立方体或者圆柱体作为体绘制的空间模型。本章使用立方体作为体纹理的载体。
注意:体纹理通过纹理坐标和三维模型进行对应,考虑到 OpenGL 和 Direct3D 使用的体纹理坐标并不相同,所以写程序时请注意到这一点。
图 44 展示了体纹理坐标在立方体上的分布,经过测试,这种分布关系是基于 OpenGL 的。在宿主程序中确定立方体 8 个顶点的体纹理坐标,注意是三元向量,然后传入 GPU ,立方体 6 个面内部点的体纹理坐标会在 GPU 上自动插值得到。
根据视点和立方体表面点可以唯一确定一条射线,射线穿越整个立方体等价于穿越体数据,并在穿越过程中对体数据等距采样,对每次得到的采样数据按照光透公式进行反复累加。这个累加过程基于 11 章讲过的透明合成公式,不过之前只是进行了简单的讲解,在本章中将针对透明度,透明合成,以及排序关系做全面阐述。
所谓的点,就在片元着色器上,会对每个像素进行着色, 也就是点
透明度、合成
透明度本质上代表着光穿透物体的能力,光穿透一个物体会导致波长比例的变化,如果穿越多个物体,则这种变化是累加的。所以,透明物体的渲染,本质上是将透明物体的颜色和其后物体的颜色进行混合,这被称为 alpha 混合技术。图形硬件实现 alpha 混合技术,使用 over 操作符。 Alpha 混合技术的公式如下所示:
其中,as 表示透明物体的透明度, cs表示透明物体的原本颜色, cd表示目标物体的原本颜色, co 则是通过透明物体观察目标物体所得到的颜色值。
如果有多个透明物体,通常需要对物体进行排序,除非所有物体的透明度都是一样的。在图形硬件中实现多个透明物体的绘制是依赖于 Z 缓冲区。在光线投射算法中,射线穿越体纹理的同时也就是透明度的排序过程。所以这里存在一个合成的顺序问题。可以将射线穿越纹理的过程作为采样合成过程,这是从前面到背面进行排序,也可以反过来从背面到前面排序,毫无疑问这两种方式得到的效果是不太一样的。
如果从前面到背面进行采样合成,则合成公式为:
其中,和分别是在体纹理上采样所得到的颜色值和不透明度,其实也就是体素中蕴含的数据;和表示累加的颜色值和不透明度
注意,很多体纹理其实并没有包含透明度,所以有时是自己定义一个初始的透明度,然后进行累加。
如果是从背面到前面进行采样合成,则公式为
沿射线进行采样
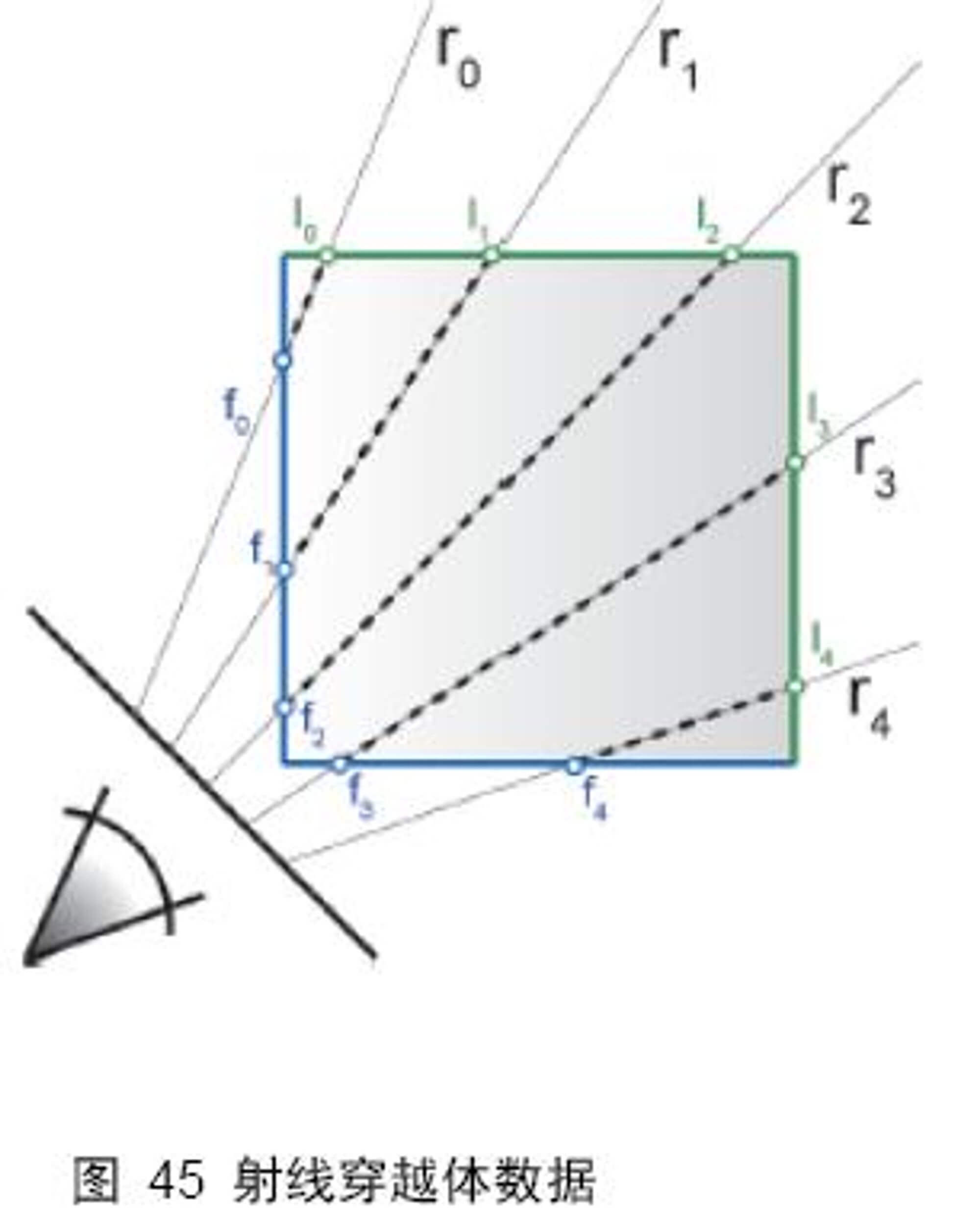
如 图 45 所示,假定光线从 F 点投射到立方体中,并从 L 点投出,在立方体中穿越的距离为 m 。当光线从 F 点投射到立方体中,穿越距离为 时进行采样,则存在公式:
其中表示立方体表面被投射点的体纹理坐标,表示投射方向,表示采样间隔,随着的增加而递增,为求得的纹理坐标,通过求得的采样纹理坐标就可以再体纹理上查询像素数据,直到或者透明度累加超过1,一条射线的采样过程才结束。
总结一下:首先需要一个确定了顶点纹理坐标的三维立方体,光线穿越立方体的过程,就是穿越体纹理的过程,在整个穿越过程中,计算采样体纹理坐标,并进行体纹理采样,这个采样过程直到光线投出立方体或者累加的透明度为 1 时结束。
纹理坐标是联系三维模型和体纹理数据之间的桥梁,通过计算光线穿越三维模型,可以计算体纹理在光线穿越方向上的变化,这就是计算采样纹理坐标的方法。
如何判断光线投射出体纹理
上一节阐述过:光线投射出体纹理,等价于光线投射出立方体。所以如何判断光线投射出体纹理,可以转换为判断光线投射出立方体。
首先计算光线在立方体中入射到出射的行进距离$ m$ ,然后当每次采样体纹理时同时计算光线在立方体中的穿越距离 ,如果 ,则说明光线射出立方体。给定光线方向,以及采样的距离间隔,就可以求出光线在立方体中的穿越距离 。
如果是在 CPU 上,距离 m 很容易通过解析几何的知识求得,直接求出光线和几何体的两个交点坐标,然后计算欧几里德距离即可。但是在 GPU 上计算光线和几何体的交点是一个老大难的问题,尤其在几何体不规则的情况下;此外,就算是规则的几何体,光线与其求交的过程也是非常消耗时间,所以通过求取交点然后计算距离的方法不予采用。
请思考一下,在 GPU 中确定点和点之间顺序关系的还有哪个量?深度值(我自问自答)。
在 GPU 中可以间接反应点和点之间关系的有两个量,一个是纹理坐标,另一个就是深度值。通常在渲染中会进行深度剔除,也就是只显示深度值小的片段。不过也存在另外一个深度剔除,将深度值小的片段剔除,而留下深度值最大的片段(深度值的剔除方法设置,在 OpenGL 和 Direct 中都有现成函数调用)。如果使用后者,则场景中渲染显示的是离视点最远的面片集合。
所以,计算距离 m 的方法如下:
- 剔除深度值较大的片段(正常的渲染状态),渲染场景深度图 frontDepth (参阅第 14 章),此时 frontDepth 上的每个像素的颜色值都代表“某个方向上离视点最近的点的距离”;
- 剔除深度值较小的片段,渲染场景深度图 backDepth , backDepth 上的每个像素的颜色值都代表“某个方向上离视点最远的点的距离”;
- 将两张深度图上的数据进行相减,得到的值就是光线投射距离 m 。
如果认真实现过第 14 章讲的 shadow Map 算法,对这个过程应该不会感到太复杂。可能存在的问题是:背面渲染很多人没有接触过。这里对背面渲染的一些细微之处进行阐述,以免大家走弯路。
通常,背面的面片(不朝向视点的面片)是不会被渲染出来的,图形学基础比较好的同学应该知道,三个顶点通常按逆时针顺序组成一个三角面,这样做的好处是,背面面片的法向量与视线法向量的点积为负数,可以据此做面片剔除算法(光照模型实现中也常用到),所以只是改变深度值的比较方法还不够,还必须关闭按照逆 / 顺时针进行面片剔除功能,这样才能渲染出背面深度图。 图 46 是立方体的正面和背面深度图。

附:在很多教程上,都是将 frontDepth 和 backDepth 相减后的值,保存为另外一个纹理,称之为方向纹理,每个像素由 r 、 g 、 b 、 a 组成,前三个通道存储颜色值,最后的 a 通道存放距离值,我觉得这个过程稍微繁琐了些,此外由于方向向量可能存在负值,而颜色通道中只能保存正值,所以必须将方向向量归一化到【 0 , 1 】空间,这个过程有可能导致数据精度的损失。基于如上的考虑,我将方向向量的计算放到片段着色程序中,通过视点和顶点位置进行计算。
这里我没有使用作者的思路,而是使用了Nvidia的hitbox
算法流程
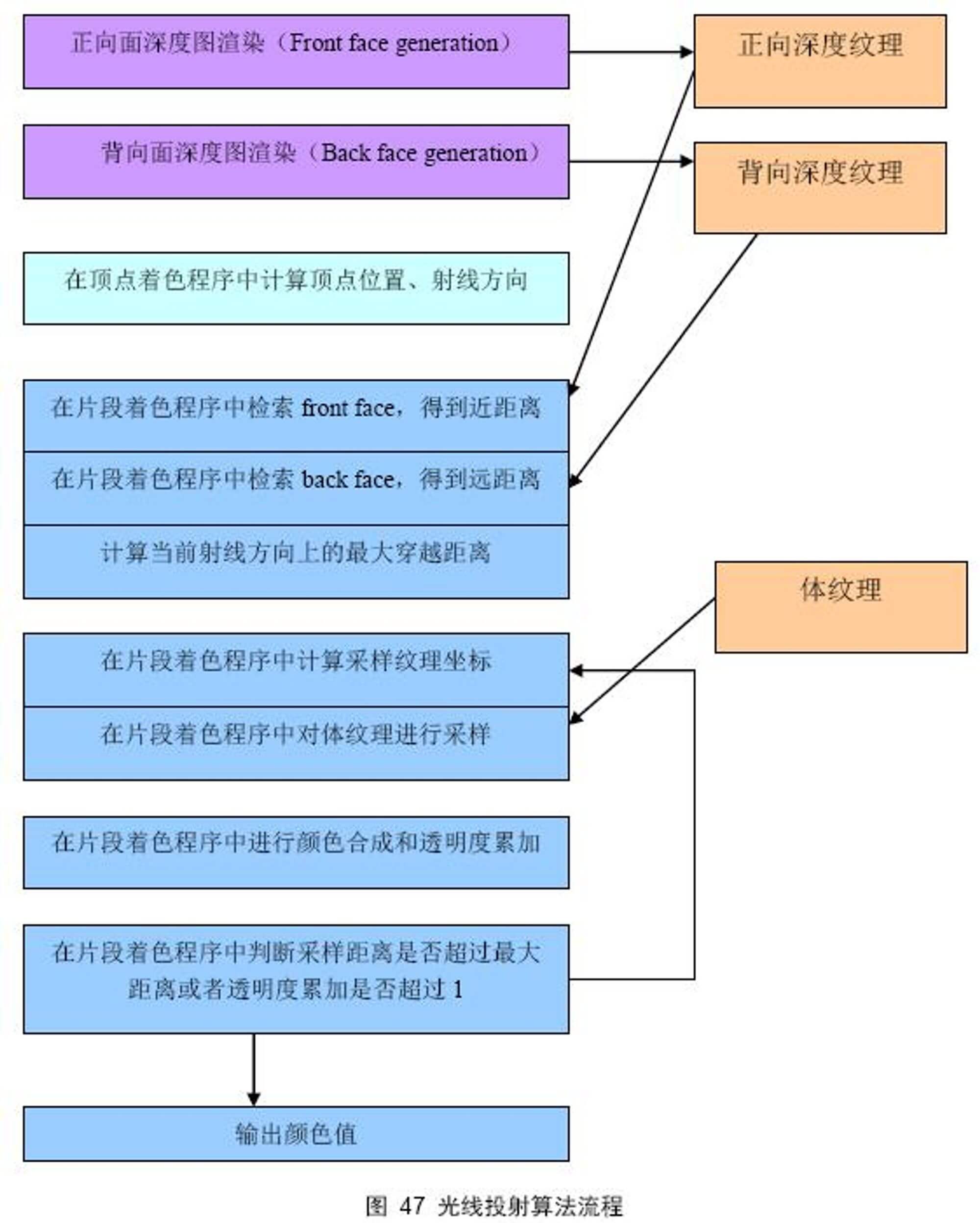
首先要渲染出正向面深度图和背向面深度图,这是为了计算射线穿越的最大距离,做为循环采样控制的结束依据;然后在顶点着色程序中计算顶点位置和射线方向,射线方向由视线方向和点的世界坐标决定,其实射线方向也可以放在片段着色程序中进行计算。然后到了最关键的地方,就是循环纹理采样、合成。
每一次循环都要计算新的采样纹理坐标和采样距离,然后进行颜色合成和透明度累加,如果采样距离超过了最大穿越距离,或者透明度累加到 1 ,则循环结束。将合成得到的颜色值输出即可。
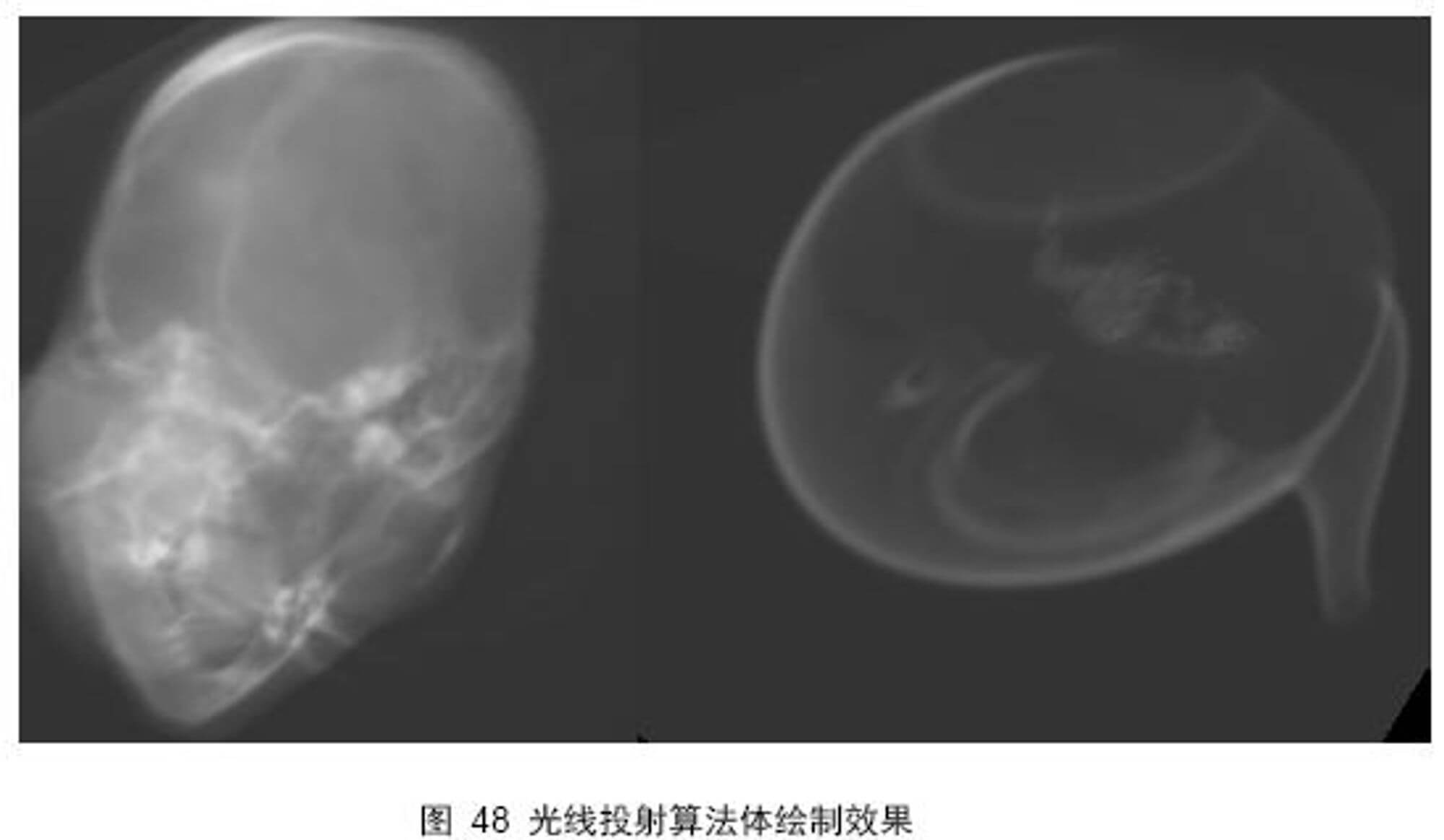
这里在实际效果上实现于作者效果一致,且Nvidia的算法不需要额外的图像
🤗 总结归纳
本书的第14 、15 章阐述了体绘制中光线投射算法的基本原理和实现流程。实际上,在此基础上可以对光线投射算法加以扩展,例如将光线投射算法和阴影绘制算法相结合,可以渲染出真实感更强的图像。
此外,有些体数据是中间是空的,在射线方向上进行采样时需要跳过空区域,这其中也需要额外的算法处理,在英文中称为“Object-Order Empty Space Skipping ”。
目前我所发现关于体绘制以及光线投射算法最好的教材是Markus Hadwiger 等人所写的“Advanced Illumination Techniques for GPU-Based Volume Raycasting ”。此书发表在SIGGRAPH ASIA2008 上,是目前所能找到最新也是非常权威的教材,共166 页。英文阅读能力比较好的同学可以尝试着看一下。
本章已经是此书的最后一章,最后希望中国的计算机科学可以真正上升到科学研究的层次,而不是一直在混沌中热衷做泥瓦匠的工作。
📎 参考文章
💡 欢迎您在底部评论区留言,一起交流~