 WebGL大场景性能优化
WebGL大场景性能优化
type
status
date
summary
slug
tags
category
password
icon
随着项目越来越复杂,很多对大场景渲染支持已经成为了“刚需”。但是,对于很多经验有限的同学,似乎找不到相关思路。那么,我们就来聊聊,如何进行 webgl 的性能优化。
📝 性能优化
首先性能优化是一个比较大的话题,会涉及多个技术点,本篇文章旨在总结相关优化思路和方向,很多阐述都是浅尝辄止,并不对每项技术点做具体的深入剖析。对于大场景来说,一般优化可以分为以下几个大的优化方向。
- 加载性能优化
- 渲染帧率优化
- 内存管理优化
- 交互操作优化
我们会根据每个大的方向,讲讲如何具体的采取哪些策略进行优化。我们首先需要知道造成渲染帧率不高的性能瓶颈在哪里。一般来说,我们使用 chrome 的开发者工具中的 performance 模块进行性能诊断,找到性能瓶颈主要是在 CPU 执行效率方面,还是在 GPU 渲染阶段的性能方面。
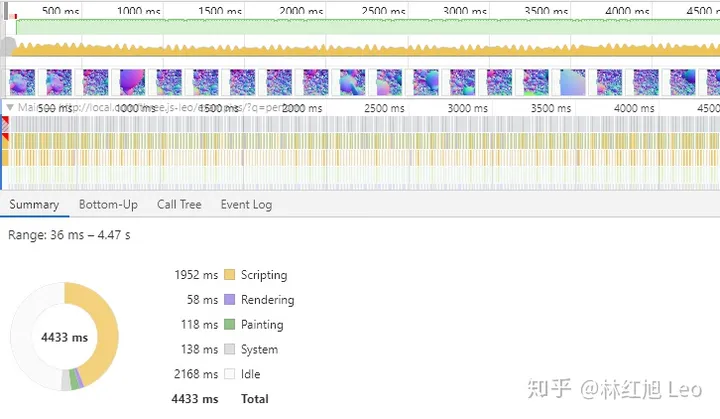
如果主要性能瓶颈在 cpu 执行阶段,我们其实非常容易找到某段 js 的执行效率较低,可以通过各种算法优化,降低 js 算法的时间复杂度,从而达到优化执行时间的目的。
1. 加载优化
受制于网络速度,对于没有缓存的大场景首次加载,可能是比较费时的,所以我们需要尽量减少加载时间,提高用户体验。
模型压缩
模型和贴图数据是整个加载过程中最为“重量级”的数据。因此,我们应当从建模阶段就定好规范,在保证外观效果的前提下,尽量使用较为精简(面数较少)的模型。在模型制作完成之后,我们也应当尽量选取一些压缩比较高的模型格式,例如 fbx、gltf 等进行模型传输。
gzip
对于一些纯字符编码的模型,如 obj,dae 等,在服务端开启 gzip 压缩,可以带来较好的压缩比。而且,使用 gzip 压缩是服务器与浏览器直接默认完成的,无需任何额外操作,对于开发者可以做到无感知。所以建议使用这类模型的都加上 gzip 压缩。其实我们可以默认所有文件都开启,因为 js css 文件经过 gzip 压缩后传输量也会小很多。
gltf draco
对于可以选取导出格式的项目来说,选取 gltf 格式加 draco 压缩的方式,可以得到较高的压缩比。不过使用 draco 压缩并不是没有代价的,有时候可能会造成模型的外观损坏。同时,解压模型也需要一些的时间。所以,对于小的模型,网络传输较快的,也就没必要上 draco 压缩了。
自定义格式
对于有能力的开发者,完全可以使用自定义的格式,将模型数据做成二进制的形式进行传输和加载,这样灵活性比较高,而且如果再前端解模型的时候使用 wasm 进行解压,可以保证自己的模型内部格式对外是一个黑盒子。
贴图压缩
上述描述的模型压缩只针对模型网格数据,不会对贴图进行处理,然而很多时候贴图文件往往大于模型。贴图尺寸也应该根据需要选取,不应该过大,一般最好不要超过 4k,保持 1024 或者 2048 较好。贴图也最好使用 2 的 n 次幂的尺寸。下面介绍如何优化用于应用程序渲染的贴图文件。
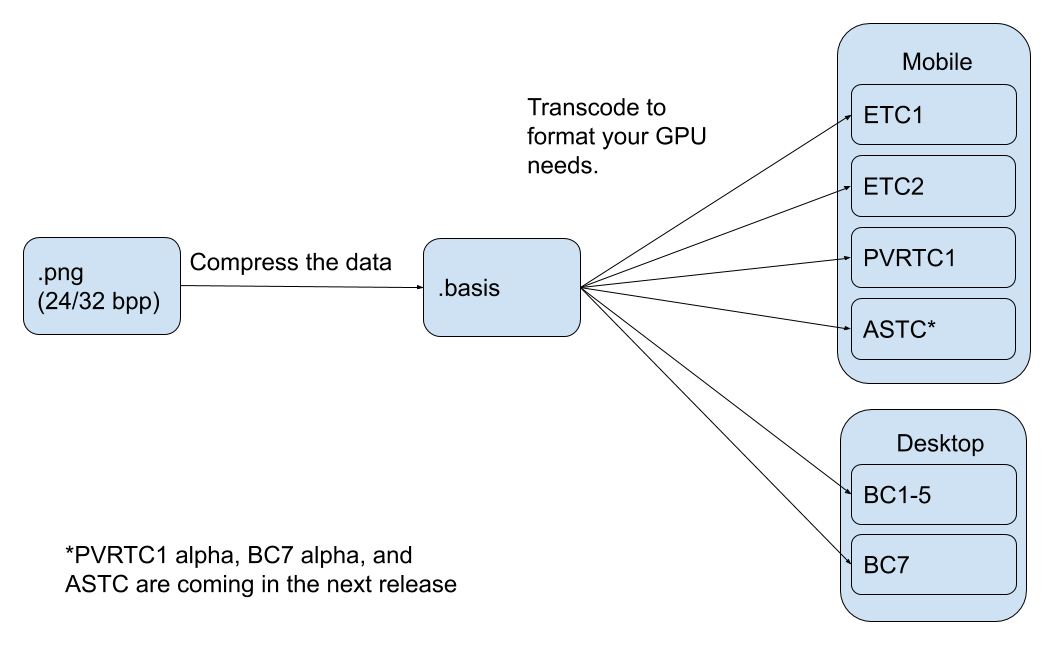
对于常见的贴图一般使用 jpg、png、tga 等格式,但是这部分格式加载完毕后,png/jpg 仍需要全部转码为纹理(texture)才能开始渲染,而具有相同尺寸的贴图纹理 GPU 占用内存大小相同,故压缩后的 png/jpg 对于渲染过程并没有优化。庆幸的是许多设备都有可直接用于渲染的 GPU 压缩纹理(compress texture)格式,压缩纹理可比由 png 直接转换的纹理减少 5 倍或以上的大小。如果直接提供压缩纹理格式,则不需要进行 png 的转码过程且可大大减少纹理内存。但由于 GPU 芯片提供商太多,设备的压缩纹理格式多种多样(例如安卓设备常用格式是 ETC1/ETC2,苹果设备是 PVRTC…)
2019 五月份,Binomial 公司和 google 联合推出了 Basis Universal 压缩 GPU 纹理技术,Basis Universal 支持多种常用的压缩纹理格式,将 png 转换为 basis 文件后,大小与 jpg 格式差不多,但在 GPU 上比 png/jpg 小 6-8 倍。在保持 GPU 性能效率的同时,提升 Web、桌面端和移动应用程序中图像传输的性能。此版本填补了图形压缩生态系统中的一个关键技术空白,同时也补充了 Draco 几何压缩的部分早期工作。

另外可以看看这篇腾讯模型和材质压缩的经验分享:如何在页面极速渲染3D模型 - Tencent ISUX Design
对于大型 3D 资源,我们一般会通过在模型设计时进行“减面”来减少模型几何体的大小,但也会带来模型精致度的缺失。如下图所示:
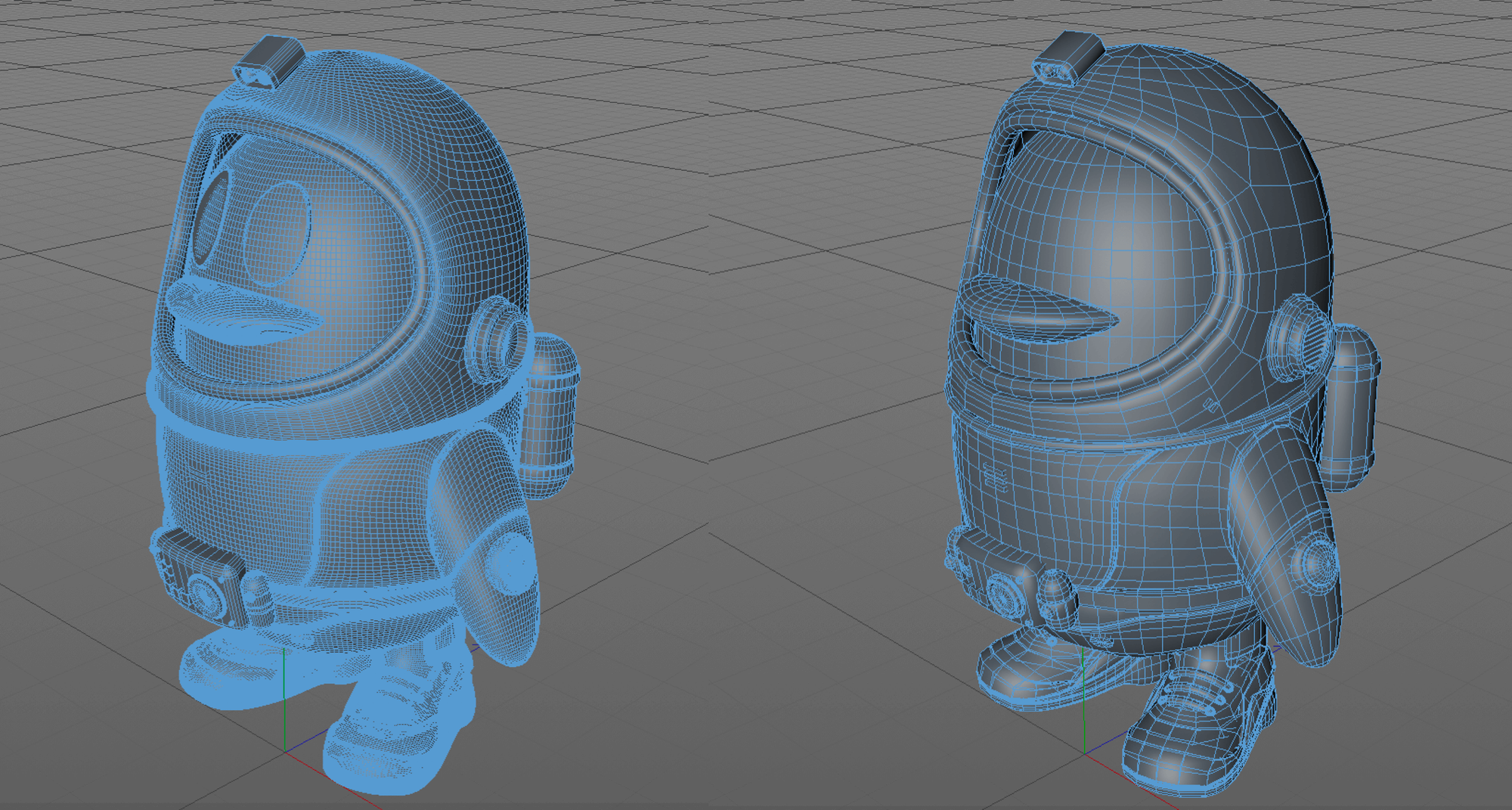
而通过 glTF 配合 Draco 压缩的方式,可以在视觉效果近乎一致的情况下,让3D模型文件成倍缩小。下面具体介绍 glTF 格式及 Draco 压缩工具。
1. 将模型导出为 glTF 格式
glTF 介绍
glTF 称为“ 3D 界的 JPEG”,使用了更优的数据结构,为应用程序实时渲染而生。glTF 有以下几大特点:
- 由现有 OpenGL 的维护组织 Khronos 推出,目的就是为了统一用于应用程序渲染的 3D 格式,更适用于基于 OpenGL 的引擎;
- 减少了 3D 格式中除了与渲染无关的冗余信息,最小化 3D 文件资源;
- 优化了应用程序读取效率和和减少渲染模型的运行时间;
- 支持 3D 模型几何体、材质、动画及场景、摄影机等信息。
glTF 导出格式有两种后缀格式可供选择:.gltf 和 .glb:
- .gltf 文件导出时一般会输出两种文件类型,一是 .bin 文件,以二进制流的方式存储顶点坐标、顶点法线坐标和贴图纹理坐标、贴图信息等模型基本数据信息;二是 .gltf 文件,本质是 json 文件,记录对bin文件中模型顶点基本数据的索引、材质索引等信息,方便编辑,可读性较好;
- .glb 文件格式只导出一个 .glb 文件,将所有数据都输出为二进制流,通常来说会更小一点,若不关心模型内的具体数据可直接选择此类型。
glTF 转换
目前有些建模工具还不具备导出 glTF 格式功能,可以输出 FBX / Collada 格式后通过以下工具进行转换:
- FBX 转 glTF
a. Facebook 推出的 FBX2glTF 命令行工具,可直接从github 官网下载 release 版本;
b. 通过 Paint 3D、Substance Painter 等可视化编辑工具进行转换。
- Collada 转 glTF
COLLADA2GLTF 命令行工具,可转换 .dae 格式的文件,从 GitHub 官网直接下载 release 版本,解压后在命令行进入目录即可调用。
2. 通过 Draco 进行压缩
Draco 及 gltf-pipeline 介绍
Draco 是 Google 推出的一个用于 3D 模型压缩和解压缩的工具库,上述介绍的 FBX2glTF 及 COLLADA2GLTF 工具也嵌入了 Draco 压缩功能,除此之外,glTF 资源可通过基于 Draco 开发的命令行工具 gltf-pipeline 进行编码压缩,gltf-pipeline 可通过 npm 的方式安装使用。使用方法如下:
Draco 压缩分析
通过 Draco 进行压缩基本上是有损的,有两点表现:
- Draco 通过 Edge breaker 3D 压缩算法改变了模型的网格数据的索引方法,缺少了原来的网格顺序;
- Draco 通过减少顶点坐标、顶点纹理坐标等信息的位数,以减少数据的存储量。
但在 gltf-pipeline 或其他压缩工具中,压缩程度可通过设置参数进行调整,如下所示:

当 --draco.compressionLevel 为0时,将保留原来的网格顺序,网格数据索引的压缩力度最小,--draco.quantizeXXXBits 可控制坐标等基本数据值的位数,位数越少压缩力度越大。由于一个三角形网格对应多个顶点坐标、顶点法线坐标、颜色坐标等数据,一般来说 --draco.quantizeXXXBits 对文件的大小影响会更大。
若不设置参数,gltf-pipeline 会直接以默认值压缩。
虽说 Draco 是有损的,但相对于直接为模型减面来说,采用 Draco 压缩方法视觉偏差会小很多。
压缩后的 glTF 模型需要通过在应用中嵌入 Draco 解码工具包,主要是对 edge breaker 算法部分进行解码,解码时间一般比编码时间少,但必须考量模型与工具包的大小对比。例如 ThreeJS 提供了 draco_decoder 模块进行解码,draco_decoder 约600KB,若模型资源文件比工具包还小,就没有必要再引入 Draco 压缩了。
3. 效果测试
我们以太空鹅模型为例,只加载模型几何体,不带入材质属性,通过ThreeJS 分别加载 FBX / glTF / 压缩后的glTF 的格式,第三种格式以默认参数压缩。测试效果对比如下:

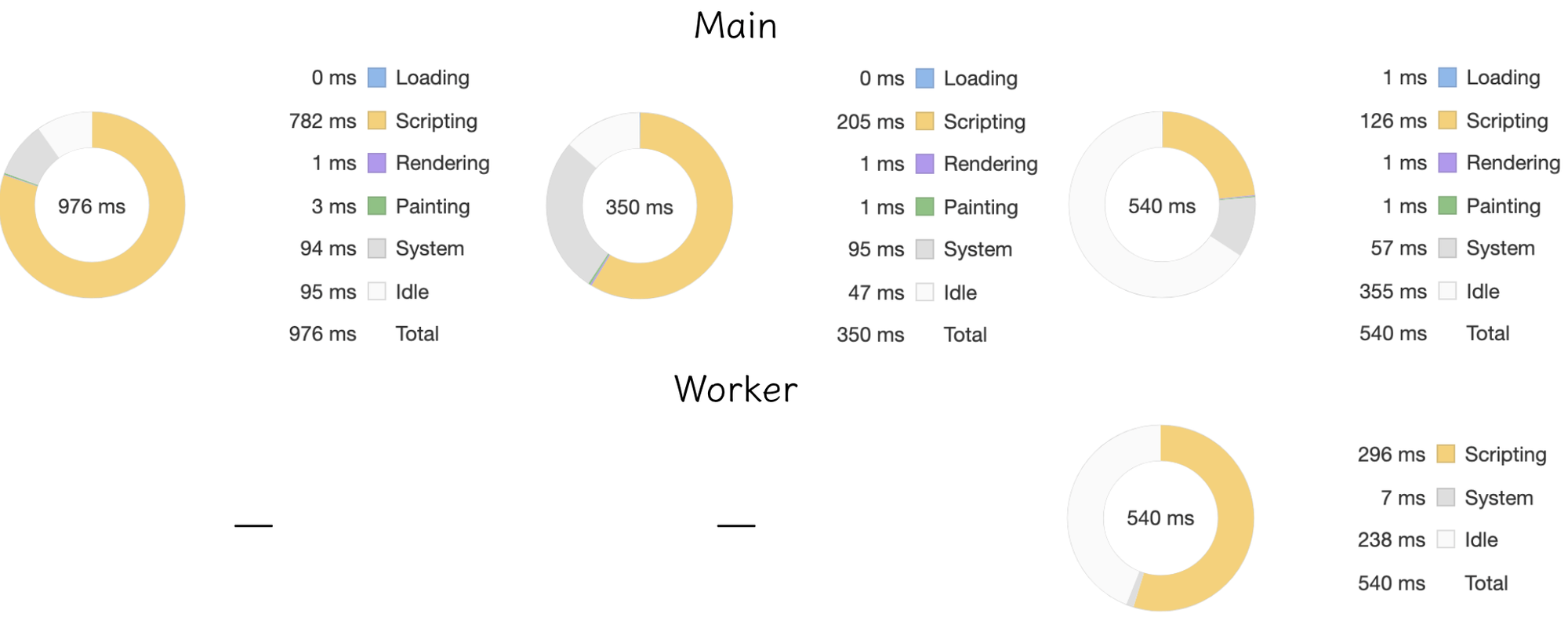
从图中可以看出,文件从 FBX 转换为 glTF 后大小差异不大,但是渲染速度有了明显提升。
另外经过压缩的 glTF 文件仅为正常 FBX 和 glTF 文件的1/10左右,而在视觉上三者几何体结构没有明显的差异,压缩后的 glTF 开启了 worker 线程做 Draco 解码,多了一小部分模型解码时间。
模型贴图优化


上述描述的模型压缩只针对模型网格数据,不会对 glTF 文件里的贴图进行处理。然而很多时候贴图文件往往大于模型。此时则需要将模型和贴图分开进行处理(建模时分开输出一个打好 UVtag 纹理坐标的“白模”和需要用到的纹理贴图)。下面介绍如何优化用于应用程序渲染的贴图文件。
1. 贴图加载过程分析
以一个基于物理引擎渲染的电视机 Demo 模型为例,一般会输出几种尺寸较大的贴图文件:颜色贴图,法线贴图,金属粗糙贴图,如下图例子所示:

输出贴图一般为 png 格式,许多同学会通过压缩 png 或者将 png 转成 jpg 格式减少纹理大小,其实这种处理方式只优化了图片加载速度,加载完毕后,png/jpg 仍需要全部转码为纹理(texture)才能开始渲染,而具有相同尺寸的贴图纹理 GPU 占用内存大小相同,故压缩后的 png/jpg 对于渲染过程并没有优化。
庆幸的是许多设备都有可直接用于渲染的 GPU 压缩纹理(compress texture)格式,压缩纹理可比由 png 直接转换的纹理减少5倍或以上的大小。如果直接提供压缩纹理格式,则不需要进行 png 的转码过程且可大大减少纹理内存。如下图方案2所示:
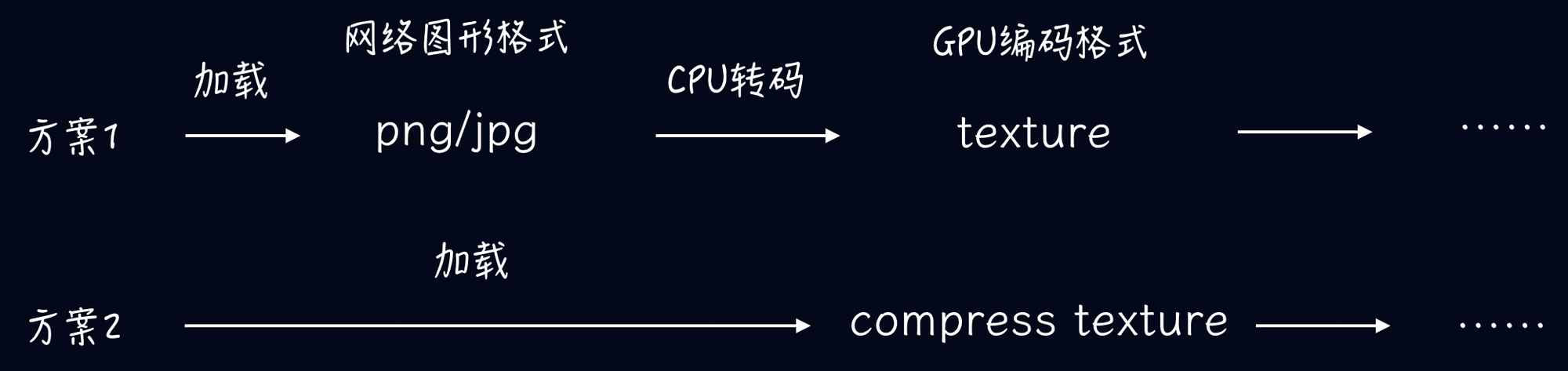
但由于 GPU 芯片提供商太多,设备的压缩纹理格式多种多样(例如安卓设备常用格式是 ETC1/ETC2,苹果设备是 PVRTC…),手动输出多种格式代价大,导致方案2较难落地。
2. Basis Universal 压缩
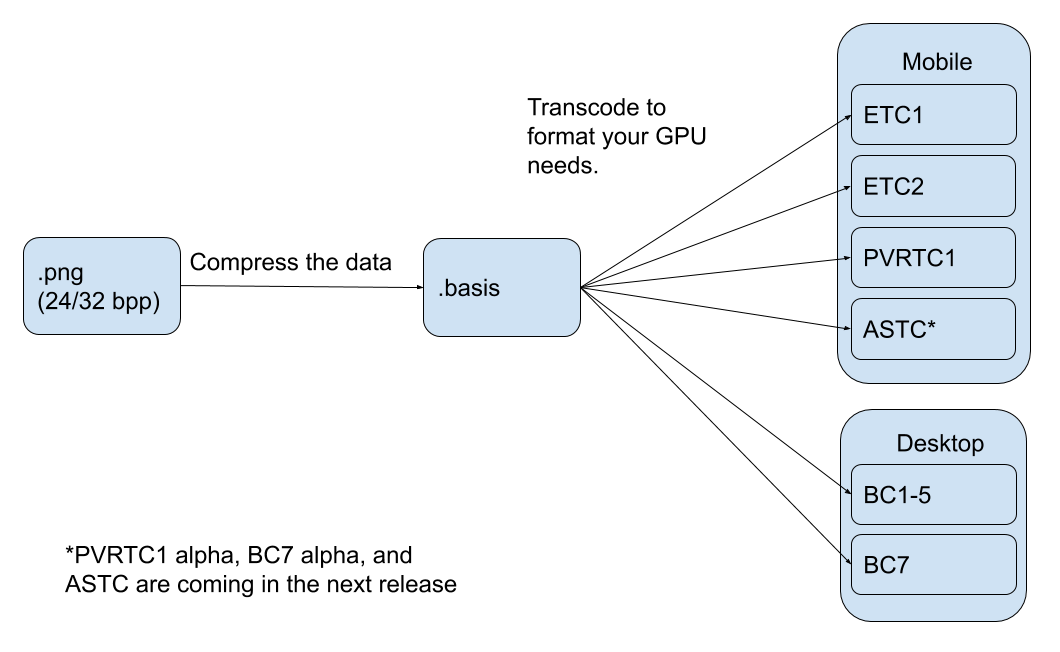
转折点在于今年五月份,Binomial 公司推出了 Basis Universal 压缩 GPU 纹理技术,Basis Universal 支持多种常用的压缩纹理格式,将 png 转换为 basis 文件后,大小与 jpg 格式差不多,但在 GPU 上比 png/jpg 小6-8倍。
应用程序加载 basis 文件后,可通过 basis 转码器快速转换成适用于设备的压缩纹理格式。如下图(图片来自Google Blog)所示:
Basis 用法也比较简单,可通过 basisu 命令行工具压缩 png,直接从github 官网下载Release版本或者通过 CMake 编译源码,以 Mac 系统为例(Windows 系统将命令改为 basis.exe),列举几种常用用法:
生成的 .basis 文件需要在程序中通过转码器转成设备的压缩纹理格式,例如在ThreeJS 中可通过 basisTextureLoader 转换,具体用法可查阅ThreeJS 官网。
3. 效果测试
为了数据更加明显,我们在Mac Chrome 浏览器performance模式下,针对同一个电视机模型利用 ThreeJS 各自加载了 4096 x 4096 大小的颜色贴图、法线贴图、金属与粗糙贴图,对比如下:

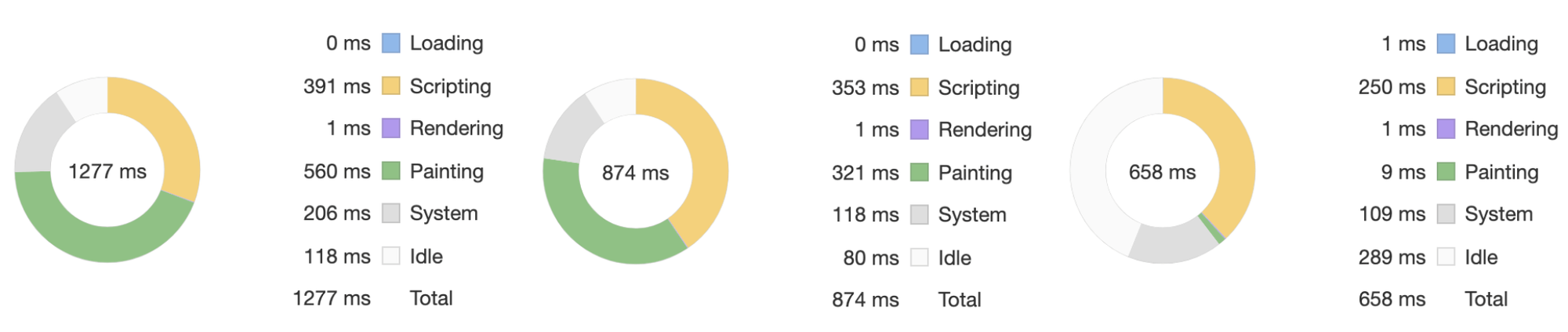
由上图使用 basis 贴图资源文件大小比 png 减少了11倍以上,同时主线程的脚本时间和绘制时间花销也小于 png/jpg 贴图。
需要注意的是,同样由于不同的压缩纹理格式不同,在 basis 文件一致的情况下,不同设备的渲染表现可能会出现不一致,需要进行多端测试,且目前部分格式不支持 alpha 通道,带半透明的颜色贴图若不生效可考虑单独拆出 alpha 贴图。
除了基于 webGL 的 H5,glTF 与 Basis 亦可用于其它基于 OpenGL 渲染的应用程序。值得期待的是,目前 Google 与 Binomial 公司正在推进 Basis Universal 与 glTF 3D 传输标准的合作,或许在不久的将来就可以迎来结合了 basis 贴图的 glTF 格式,不需要做另外的处理可以直接导入模型到应用程序中。
分包流式加载
对于大的场景,特别是 BIM 或者 GIS 场景,如果把所有模型全部加装完成了再展示,可能会让用户等待时间过久。所以,我们可以采取分包流式加载的方式,每个包加载一部分的模型,加载解析完成后即丢到渲染主线程中进行渲染。这种方式大家之前经常看到的是百度地图的数据的分片加载。
想要达到这样的效果,我们一般会使用 worker 进行数据的加载和解析处理,这样保证了加载的线程和主线程是隔离的,不会产生加载解析模型过程中产生的 UI 卡顿。同时,如果我们想要达到并行加载和解析的效果,可以开多个 worker 进行多线程的同时加载解析工作。
使用缓存
优化完了首次加载的耗时操作,我们可以继续优化加载,采用各种缓存技术是也常见的加载优化方法,其中包括使用 cdn 文件服务,浏览器文件缓存、indexeddb 前端缓存等。
使用 CDN
对于加载来说,除了文件本身大小因素,我们不得不考虑的一点就是文件所放置的服务器带宽问题。如果模型场景都放在一台服务器上,加载过程中必定会对服务器的带宽带来一定压力。所以使用 cdn 做静态资源的文件服务,变得顺理成章。
使用 indexedDB
因为模型数据变化其实不大,所以再首次加载的过程中,我们可以使用 indexedDB 做前端的数据缓存。indexedDB 具有良好的查询性能,超大的存储空间(理论上磁盘剩余空间的一半左右),以及支持二进制存储等优良特性,比较适合做前端模型以及贴图数据的缓存。
在使用了 indexeddb 做前端缓存之后,可以做到首次加载之后,对大场景的数据进行秒级加载的超高性能 ,大大提升了用户频繁打开大场景的操作体验。
因此,有些 Webgl 引擎(例如 Babylon.js )已经在引擎级别对 indexedDB 缓存做了支持。开发者只需要简单配置,即可打开缓存,优化加载体验。
2. 渲染帧率优化
在加载优化完成之后,我们继续聊聊如何进行大场景的渲染优化。如果主要性能瓶颈在 GPU 渲染部分,那么我们就需要仔细看看到底是什么造成的渲染瓶颈。我们可从以下方案入手,看看是否已经使用相关优化手段。总的来说,目的是尽量减少 drawcall(opengl state 切换带来的性能损耗),减少向 GPU 提交的数据量(带宽压力)。
各种剔除 Culling
为了达到尽量减少 DrawCall 的目的,我们应当尽量的做好剔除工作,将最少的数据提交给 GPU 进行渲染。一般常见的剔除方式有视椎体剔除,背面剔除、遮挡剔除等。
视椎体剔除(Frustum Culling):一般是指只有在视椎体内的物体才能被渲染出来,不在视椎体内的物体将被剔除不作渲染。这也比较符合我们一般的视觉逻辑,不在可见范围内的物体,渲染了也看不见,纯粹属于性能浪费。这部分的剔除,大部分的引擎都已经自带了,而且都是默认开启的。如果需要自己实现,算法也比较简单,一般是遍历视椎体的 6 个面,算出物体的中心到面的最小距离(带正负方向的)与包围球的半径做比较,如果小于半径,就表示在外面。
背面渲染剔除(Backface Culling) :一般来讲,渲染引擎大多会开启背面剔除。原生 webgl 中使用
gl.enable(gl.CULL_FACE); 来开启背面剔除。在 threejs 中可以使用 material 的 side 属性指定 front 进行单面渲染。遮挡剔除(Occlusion Culling) :遮挡剔除是指在相机剔除后,在视野范围内仍然有许多物体直接有遮挡关系的,不需要进行渲染,虽然 gpu 有深度测试,会将有遮挡的物体进行剔除,但是我们仍然希望在提交 GPU 之前对遮挡关系进行判断,提前剔除掉一些东西,减少渲染压力。
遮挡剔除相关的文章:
这篇文章也非常好 里面描述了如何用八叉树和 zbuffer 配合做剔除
webgl2 OcclusionQuery 遮挡查询
合批 batch
除了剔除以外,合批次提交也能提高渲染性能,原因也非常的简单,就是合批后提交 GPU 的 DrawCall 减少了。对于合批,我们应该遵循以下原则。
首先是材质相同的进行 batch,材质不同的无法进行 batch。一个 batch 其实就是一个 drawcall,对应的其实一种材质,不同种材质效果需要使用不同的 shader 实现所以无法实现合批展示。
其次 batch 的定点格式限制问题。因为 webgl 的 index 数据使用的 short 类型,所以最好不要超过 65535 个顶点索引。但是,由于 webgl 的扩展
OES_element_index_uint 已经有了非常良好的兼容性(99%兼容),所以其实你已经可以使用超过 65535 个顶点 index。stackoverflow 关于顶点限制的讨论:https://stackoverflow.com/questions/4998278/is-there-a-limit-of-vertices-in-webgl
如果你使用的 threejs,可以选择使用 geometry 的 merge 方法在前端进行合并 batch,或者手工进行顶点 loop 循环合并顶点,其实原理差不多。
instance
instance 实例化其实也是渲染优化中常用的技术,特别适合那些外观一致大量重复的渲染。比如小树组成的森林,一个发布会场景中的大量椅子等等。在 instance 渲染的时候,我们不需要传入大量的顶点数据(只需要传入每个 instance 的 matrix 数据),而是共享一份顶点数据,这样可以大大降低显存的使用率,降低显存带宽。
在 webgl 中我们使用的是
ANGLE_instanced_arrays扩展来实现 instance 渲染。但是值得注意的是,instance 的使用所带来一些额外处理,比如单个物体的选择操作等问题。LOD
LOD(Level of Details)技术指的是将场景中的模型按不同精度分为 N 套,按照模型与相机的距离远近,动态切换模型的精度,距离相机较近的模型采用精细模型展示,而距离相机较远的模型使用较为粗糙的模型进行展示。对于大的场景,使用 LOD 技术也是一个有效提升帧率的手段,可以有效减少整个场景中的渲染三角面数。
使用 LOD 技术一个非常重要的问题是如何生成多套不同精度的模型。一般来说有一下几个方案:
一是在建模软件中,使用减面工具,直接生成多套模型,这部分一般是美术建模人员来完成。虽然程序少了很多事儿,但是通用性较差,自动化程度较低。
二是选用开源的减面方案进行程序减面。一般来说可以选取一些 QEM 算法减面,使用程序进行减面。但是一般这类算法都有一些局限,比如贴图问题,破面问题。需要程序不断调试,找到比较合适的参数。
Fast-Quadric-Mesh-Simplification
sp4cerat • Updated Mar 28, 2024
三就是使用商业的 sdk 进行减面。一般常用的是 simplygon、instlod 等都是比较成熟的商用减面工具,也广泛的使用在游戏等行业。
另外,很多游戏引擎也自带一些减面工具,比如 u3d、ue4 等都支持 LOD 减面。
3. 内存管理优化
对于重型 webgl 应用,特别是 BIM、GIS 场景,有时候,我们需要加载多个大型模型,例如 cesium 还需要能够支持整个地球数据的加载。这就需要我们对内存有着较好的控制。
一方面,我们需要在不适用对象的时候,及时销毁对象,释放 JS 内存。同时对于模型数据,大量的顶点、法线等等 buffer 数据也是非常占用内存的。我们可以在 js 推送完数据之后,将这部分数据从内存中释放掉,从而降低 JS 的内存压力。对于 v8 引擎来说 32 位的 JS heap 最多能到 3.8G 左右,如果不及时释放内存,很容易内存爆掉,导致浏览器 crash。
如果使用 threejs 进行渲染,
BufferAttribute包含一个onUpload回调函数,在数据推送到 GPU 之后调用。我们可以在回调函数中释放掉 js 中的数据。值得注意的是,这个回调函数只在第一次的时候有用,在 attribute 更新 update 的时候,并不会触发,笔者认为这是个 bug 提交了 pr 给 threejs,不过似乎 threejs 的作者doob并不十分感冒,最终没有 merge 这个 pr。另一方面,在大场景的渲染下,我们要尽量引导客户使用 64 位的浏览器 chrome 或者 Firefox,这样可以最大限度的使用 js 内存,防止 V8 js Heap 爆了的情况。
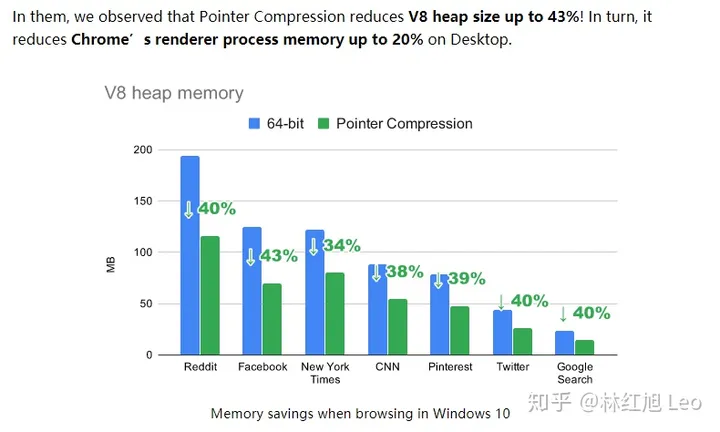
好消息是,最新的 v8 又加入了指针压缩,将内存的使用量降低了不少。
4. 交互操作优化
除了加载,渲染等方面,普通的交互操作在大场景的条件下,也容易带来非常大的挑战。交互操作中一个常见的问题就是模型拾取。一般普通的三维场景中,我们常用的是射线拾取的方式,遍历场景中的模型,进行模型的相交测试。但是由于场景非常大,可能会导致整个遍历非常耗时。所以我们要对拾取进行优化。常见的优化方式有使用 GPU 拾取、以及使用八叉树进行加速遍历等方式。
gpu 拾取 一般做法是给每个 mesh 一种颜色 然后渲染绘制一遍,在鼠标点所在的位置调用 readPixel 读取像素颜色,根据颜色与模型的对应关系,反推当前拾取到的颜色对应的 mesh。
八叉树优化 一般是使用八叉树的数据结构,将整个场景中的模型放入八叉树的不同 cell 中,由于八叉树类似空间范围内的二分查找,所以能够非常迅速将查找范围落在最终需要遍历的模型上。从而达到加速模型场景遍历的目的。对于八叉树的实现网上有很多的版本,大家可以参考,一般笔者使用的是稀松八叉树。
欢迎您在底部评论区留言,一起交流~